
Créer son Propre Modèle Prédictif pour les Coupes
Les bookmakers ne fixent pas leurs cotes au hasard. Derrière chaque chiffre affiché se cache un modèle mathématique sophistiqué qui évalue les probabilités de chaque issue possible. La bonne nouvelle, c’est que vous pouvez construire votre propre modèle prédictif sans être data scientist ni disposer de ressources informatiques considérables. Un tableur Excel et quelques heures de travail suffisent pour créer un outil qui transformera votre approche des paris sur les compétitions à élimination directe.
L’objectif d’un modèle prédictif n’est pas de deviner l’avenir avec certitude. Personne ne peut prédire qu’un club de National battra le PSG en seizième de finale de Coupe de France. L’ambition est plus modeste mais plus réaliste : estimer des probabilités qui, comparées aux cotes des bookmakers, révèlent des opportunités de value bet. Quand votre modèle estime qu’une équipe a 40% de chances de gagner alors que la cote proposée implique seulement 30% de probabilité, vous avez potentiellement identifié un pari à valeur positive.
Les fondements théoriques : la distribution de Poisson
La plupart des modèles prédictifs de football reposent sur la distribution de Poisson, un concept statistique qui modélise la probabilité qu’un nombre donné d’événements se produise dans un intervalle de temps fixe. Appliquée au football, cette distribution permet d’estimer la probabilité que chaque équipe marque 0, 1, 2, 3 buts ou plus dans un match. En combinant ces probabilités, on obtient une matrice de tous les scores possibles avec leur probabilité associée.
La beauté de la distribution de Poisson réside dans sa simplicité : elle ne nécessite qu’un seul paramètre, lambda, qui représente le nombre moyen d’événements attendus. Pour un match de football, vous calculerez deux lambda distincts : l’espérance de buts de l’équipe à domicile et celle de l’équipe visiteuse. Ces valeurs dépendent de quatre facteurs que votre modèle devra quantifier : la force offensive de chaque équipe, leur force défensive respective, et l’avantage du terrain.
La formule de Poisson s’exprime ainsi : P(X = k) = (λ^k × e^(-λ)) / k!, où P(X = k) représente la probabilité de marquer exactement k buts, λ est l’espérance de buts et e la constante d’Euler (environ 2.718). Ne vous laissez pas intimider par cette notation : Excel dispose d’une fonction intégrée LOI.POISSON qui effectue ce calcul automatiquement.
Collecter et préparer les données
Tout modèle prédictif repose sur des données historiques. Pour construire un modèle efficace sur les matchs de coupe, vous devrez rassembler les résultats des saisons précédentes. Le site Football-Data.co.uk propose des fichiers CSV gratuits couvrant les principales ligues et coupes européennes sur plusieurs décennies. Ces fichiers incluent non seulement les scores finaux, mais également les cotes de clôture des bookmakers, ce qui vous permettra de tester rétroactivement la performance de votre modèle.
La spécificité des compétitions à élimination directe complique légèrement la collecte de données. Contrairement aux championnats où chaque équipe affronte tous ses adversaires, les matchs de coupe opposent des équipes qui ne se rencontrent parfois jamais en conditions normales. Un club de Régional 1 qui reçoit un pensionnaire de Ligue 1 constitue une configuration rare dont les données historiques sont limitées. Votre modèle devra donc s’appuyer sur des indicateurs plus généraux : performances en championnat, résultats récents, statistiques de buts marqués et encaissés.
Organisez vos données dans un tableur avec une structure claire. Chaque ligne représente un match, chaque colonne une variable : date, équipe à domicile, équipe à l’extérieur, buts domicile, buts extérieur, division de chaque équipe, et éventuellement des variables contextuelles comme le tour de la compétition ou le fait que le match soit joué sur terrain neutre. Cette organisation facilitera les calculs ultérieurs et les mises à jour régulières de votre modèle.
Calculer les forces offensives et défensives
Le cœur de votre modèle réside dans l’évaluation des forces de chaque équipe. L’approche classique consiste à calculer des indices relatifs qui comparent les performances d’une équipe à la moyenne de la ligue. Pour la force offensive, divisez le nombre moyen de buts marqués par l’équipe par la moyenne de buts marqués dans la compétition. Pour la force défensive, effectuez le même calcul avec les buts encaissés.
Prenons un exemple concret avec des données de Ligue 1. Si la moyenne de buts par match à domicile est de 1.5 et qu’une équipe marque en moyenne 2.0 buts à domicile, sa force offensive à domicile sera de 2.0/1.5 = 1.33. Cette équipe marque donc 33% de plus que la moyenne. Si elle encaisse 1.0 but par match alors que la moyenne est de 1.2, sa force défensive sera de 1.0/1.2 = 0.83, ce qui signifie qu’elle concède 17% de buts en moins que la moyenne.
Les compétitions de coupe introduisent une complexité supplémentaire : les équipes proviennent de divisions différentes. Comment comparer la force offensive d’un club de National 2 à celle d’un club de Ligue 1 ? Une approche pragmatique consiste à appliquer des coefficients de niveau. Les données historiques des matchs interdivisions permettent d’estimer que, en moyenne, un club de Ligue 1 marque X fois plus de buts qu’un club de National contre un adversaire équivalent. Ces coefficients, calibrés sur votre base de données, ajusteront les forces brutes calculées.
Construire la matrice de probabilités dans Excel
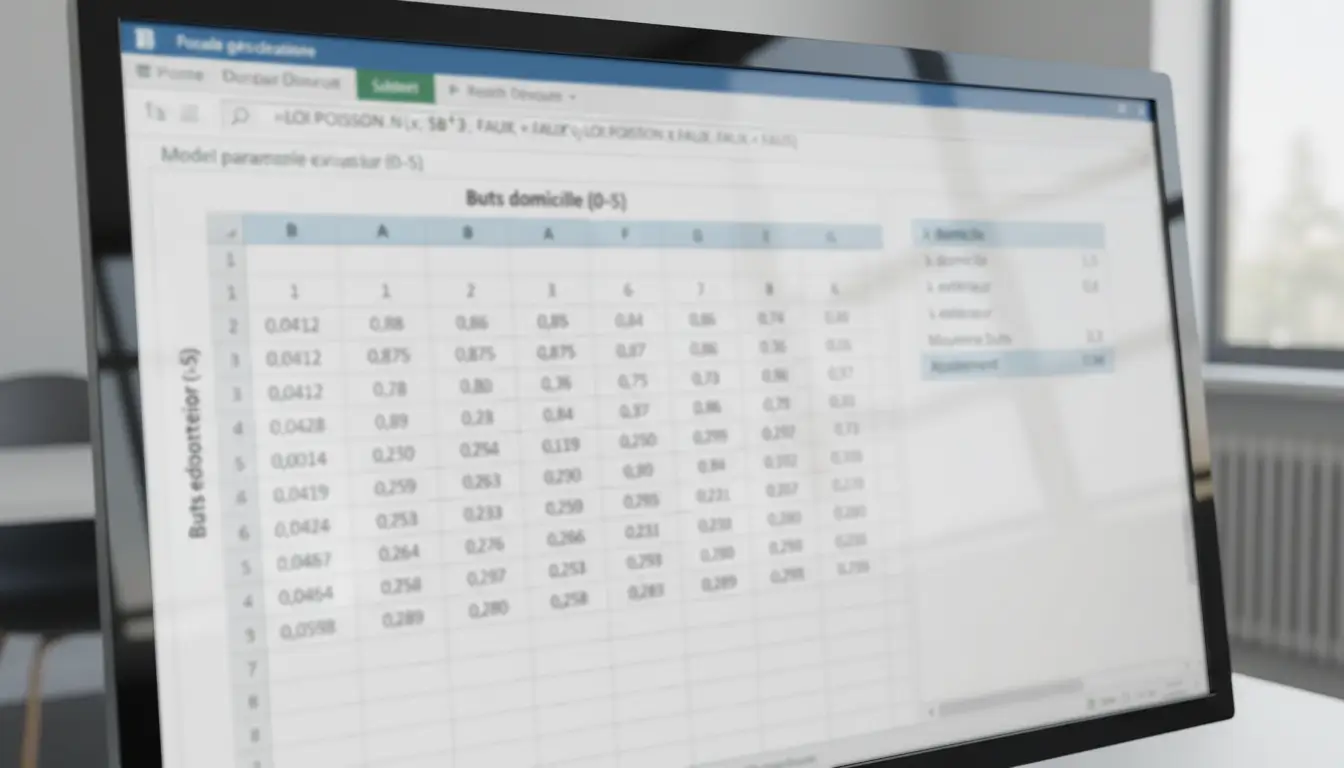
Une fois les forces offensives et défensives calculées, vous pouvez estimer l’espérance de buts pour chaque équipe dans un match donné. La formule combine les quatre facteurs mentionnés précédemment. Pour l’équipe à domicile : Lambda_dom = Force_att_dom × Force_def_ext × Moyenne_buts_domicile. Pour l’équipe à l’extérieur : Lambda_ext = Force_att_ext × Force_def_dom × Moyenne_buts_exterieur.
Créez ensuite une matrice 6×6 (ou plus si vous souhaitez inclure des scores plus élevés) qui croise les probabilités de chaque score. En colonne, les buts de l’équipe à domicile de 0 à 5+. En ligne, les buts de l’équipe à l’extérieur de 0 à 5+. Chaque cellule contient le produit des probabilités de Poisson correspondantes, calculées avec la fonction =LOI.POISSON(nombre_buts;lambda;FAUX).
Cette matrice vous permet de calculer toutes les probabilités utiles aux paris. La probabilité de victoire à domicile correspond à la somme des cellules où le score domicile est supérieur au score extérieur. La probabilité de match nul correspond à la diagonale (0-0, 1-1, 2-2, etc.). La probabilité de victoire à l’extérieur correspond aux cellules restantes. Pour les marchés Over/Under, additionnez les cellules dont le total de buts correspond à votre seuil.
Intégrer les spécificités des matchs de coupe
Les compétitions à élimination directe présentent des caractéristiques qui nécessitent des ajustements à votre modèle de base. La motivation constitue un facteur difficile à quantifier mais indéniablement présent. Un club amateur qui reçoit une équipe professionnelle en Coupe de France joue généralement le match de sa vie, tandis que le visiteur peut aborder la rencontre avec moins d’intensité, surtout si un match de championnat important approche.
L’effet « Petit Poucet » se traduit statistiquement par une surperformance des équipes de divisions inférieures par rapport à ce que leurs statistiques en championnat suggèrent. Intégrez un coefficient de correction qui augmente légèrement la force des outsiders dans les confrontations interdivisions. Ce coefficient, que vous calibrerez sur les données historiques, reflète l’engagement supplémentaire et l’effet de surprise qui caractérisent ces rencontres.
Les conditions de jeu méritent également votre attention. Un match disputé sur un terrain synthétique avantage l’équipe habituée à cette surface. Les petits clubs de divisions inférieures évoluent souvent sur ce type de terrain, ce qui constitue un facteur d’égalisation face aux équipes professionnelles habituées aux pelouses naturelles. Ajoutez une variable binaire dans votre modèle qui bonifie légèrement l’équipe locale lorsque le match se joue sur synthétique.
Convertir les probabilités en cotes et identifier les value bets
Votre modèle produit des probabilités, mais les bookmakers affichent des cotes. La conversion entre ces deux formats est straightforward : Cote = 1 / Probabilité. Si votre modèle estime la victoire d’une équipe à 60%, la cote juste correspondante est 1/0.60 = 1.67. Cette cote ne tient pas compte de la marge du bookmaker, qui réduira les cotes réelles en dessous de cette valeur théorique.
Le value bet apparaît lorsque la cote proposée par le bookmaker est supérieure à la cote juste calculée par votre modèle. Si votre modèle donne 1.67 et que le bookmaker propose 1.85, vous avez identifié une opportunité avec une espérance positive. Sur le long terme, parier systématiquement sur ces situations devrait générer des profits, à condition que votre modèle soit bien calibré.
La notion de valeur attendue (expected value ou EV) quantifie l’intérêt d’un pari. La formule est simple : EV = (Probabilité × Gain) – (1 – Probabilité) × Mise. Pour une mise de 10€ sur une cote de 1.85 avec une probabilité estimée de 60% : EV = (0.60 × 8.50) – (0.40 × 10) = 5.10 – 4 = +1.10€. Une EV positive indique un pari théoriquement profitable. Créez une colonne dans votre tableur qui calcule automatiquement l’EV de chaque pari potentiel.
Tester et améliorer votre modèle
Un modèle n’a de valeur que s’il produit des résultats probants sur des données qu’il n’a jamais vues. La méthodologie de backtesting consiste à appliquer votre modèle sur des matchs passés et à simuler les paris que vous auriez effectués. Comparez ensuite les résultats simulés aux résultats réels pour évaluer la rentabilité théorique de votre approche.
Divisez votre base de données en deux parties : un ensemble d’entraînement (environ 80% des données) qui servira à calibrer les paramètres du modèle, et un ensemble de test (les 20% restants) qui évaluera sa performance. Cette séparation évite le piège du surapprentissage, où un modèle s’adapte parfaitement aux données historiques mais échoue sur les nouveaux matchs.
Les métriques de performance à suivre incluent le taux de réussite (pourcentage de paris gagnés), le ROI (profit divisé par le total des mises) et le score de Brier (qui mesure la qualité des probabilités prédites). Un bon modèle de football affiche typiquement un ROI compris entre 2% et 10% sur le long terme, ce qui peut sembler modeste mais représente une performance significative dans un marché aussi efficient que celui des paris sportifs.
Passer à Python pour un modèle plus sophistiqué
Excel convient parfaitement pour débuter, mais ses limitations apparaissent rapidement lorsque vous souhaitez sophistiquer votre approche. Python offre une puissance de calcul supérieure et l’accès à des bibliothèques spécialisées qui automatisent de nombreuses tâches. La courbe d’apprentissage est raisonnable pour quelqu’un qui maîtrise Excel, et les ressources pédagogiques gratuites abondent sur internet.
La bibliothèque Pandas simplifie la manipulation des données tabulaires. Quelques lignes de code suffisent pour importer un fichier CSV, filtrer les matchs de coupe, calculer les statistiques agrégées et produire les probabilités pour un nouveau match. Scikit-learn propose des algorithmes de machine learning qui dépassent les capacités de la distribution de Poisson, notamment les forêts aléatoires et les réseaux de neurones.
L’automatisation constitue l’avantage décisif de Python. Plutôt que de mettre à jour manuellement votre tableur chaque semaine, un script Python peut collecter automatiquement les nouveaux résultats, recalculer les forces de chaque équipe et générer les probabilités pour les matchs à venir. Cette automatisation libère du temps pour l’analyse et l’amélioration continue du modèle.
Le passage à Python ne signifie pas abandonner Excel. De nombreux parieurs utilisent Python pour les calculs intensifs et exportent les résultats vers un tableur pour la visualisation et la prise de décision finale. Cette approche hybride combine le meilleur des deux mondes : la puissance algorithmique de Python et le confort d’utilisation d’Excel.
Les limites inhérentes à tout modèle prédictif
Aucun modèle ne peut capturer l’intégralité des facteurs qui influencent l’issue d’un match de football. Les blessures de dernière minute, les conditions météorologiques, la dynamique psychologique d’un vestiaire ou les décisions arbitrales échappent à toute modélisation statistique. Votre modèle constitue un outil d’aide à la décision, pas un oracle infaillible.
Les matchs de coupe amplifient ces limitations. Les confrontations interdivisions, rares par nature, fournissent peu de données pour calibrer les coefficients de niveau. L’effet coupe, cette motivation supplémentaire des équipes amateurs, varie considérablement d’un match à l’autre selon des facteurs difficilement quantifiables. Votre modèle identifiera des tendances générales, mais chaque match conserve une part irréductible d’incertitude.
L’humilité épistémique doit guider votre utilisation du modèle. Quand les probabilités calculées s’écartent significativement de votre intuition sportive, prenez le temps d’analyser la source de cette divergence. Parfois, votre modèle a capté une information que vous avez négligée. D’autres fois, c’est votre connaissance qualitative du football qui détecte un facteur que les statistiques ne reflètent pas. La combinaison judicieuse de l’analyse quantitative et du jugement qualitatif constitue l’approche la plus robuste pour parier sur les compétitions de coupe.